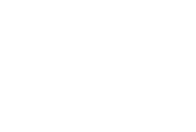

")

To train an AI, huge datasets are neccesarry. The 3D software Blender can be used to create such datasets or augment existing ones.
Joerg Osarek created a project for the Deutsche Bahn Netz AG in cooperation with the Fraunhofer IIS, which resulted in 3D Twinz Trainbow. BlenderDiplom created synthetic datasets in order to train an image recognition ML model using Blender.
The goal was to enhance an existing dataset of aerial forest photographs with additional 3D-rendered images to improve the classifier. For this task, we created virtual models of trees and scattered them using geometry nodes. Our setup also took procedurally generated hillsides and slopes into account, something that the original trainig set was lacking.

The setup included the option to add clearings. An image suitable for training had at least 51% coverage with one species of tree. Our setup can guarantee that, because we could set the parameters for the procedural placement of the tree models.
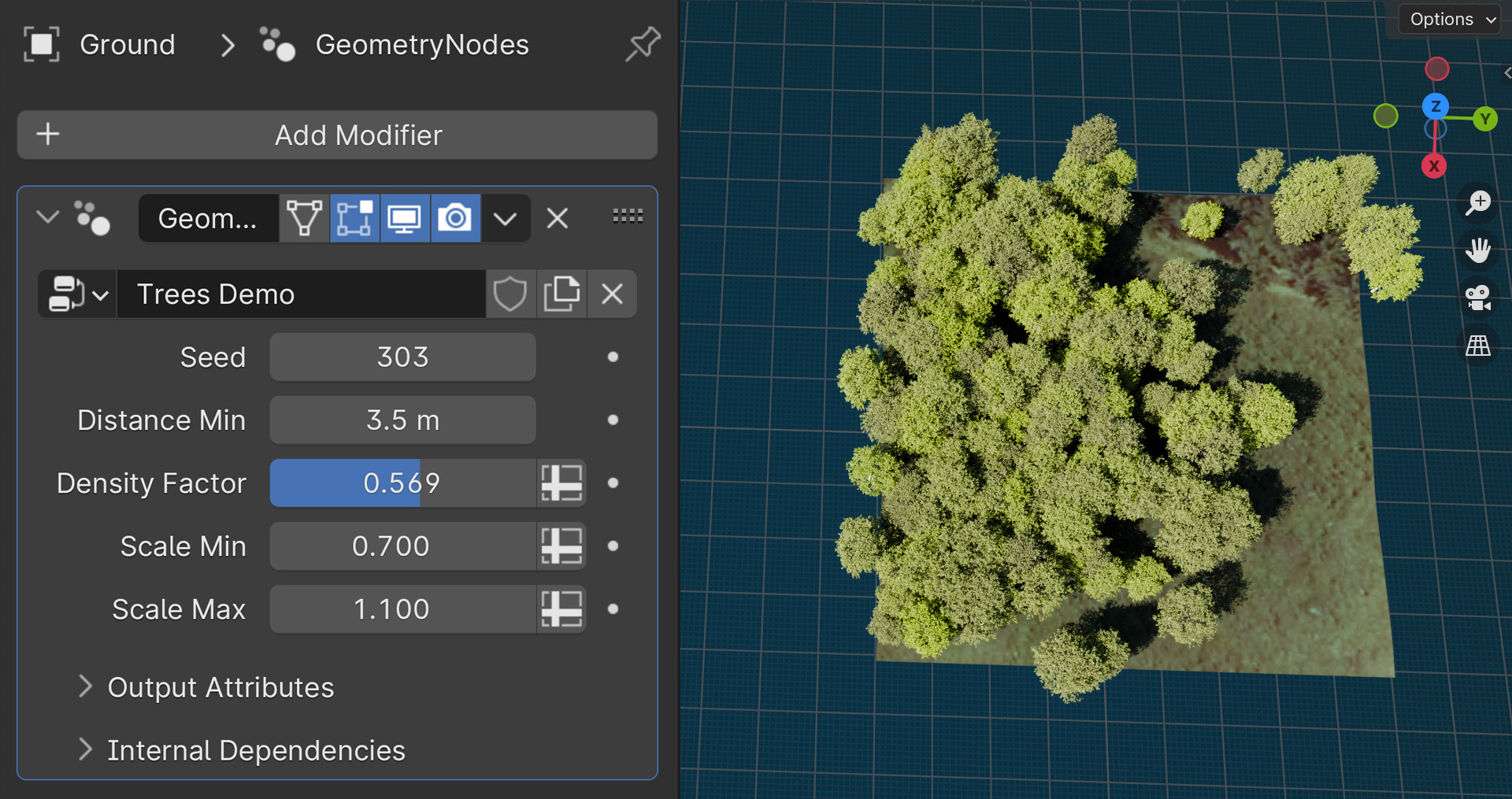
Creating thousands of forest scenes procedurally also meant that we had to render thousands of different scenes, each with different configurations. No suprise that Blender would crash every once in a while during the rendering process. To counter that, we used our in-house tool The Blender Render Reviver to monitor the rendering process and restart Blender when it detected a crash.
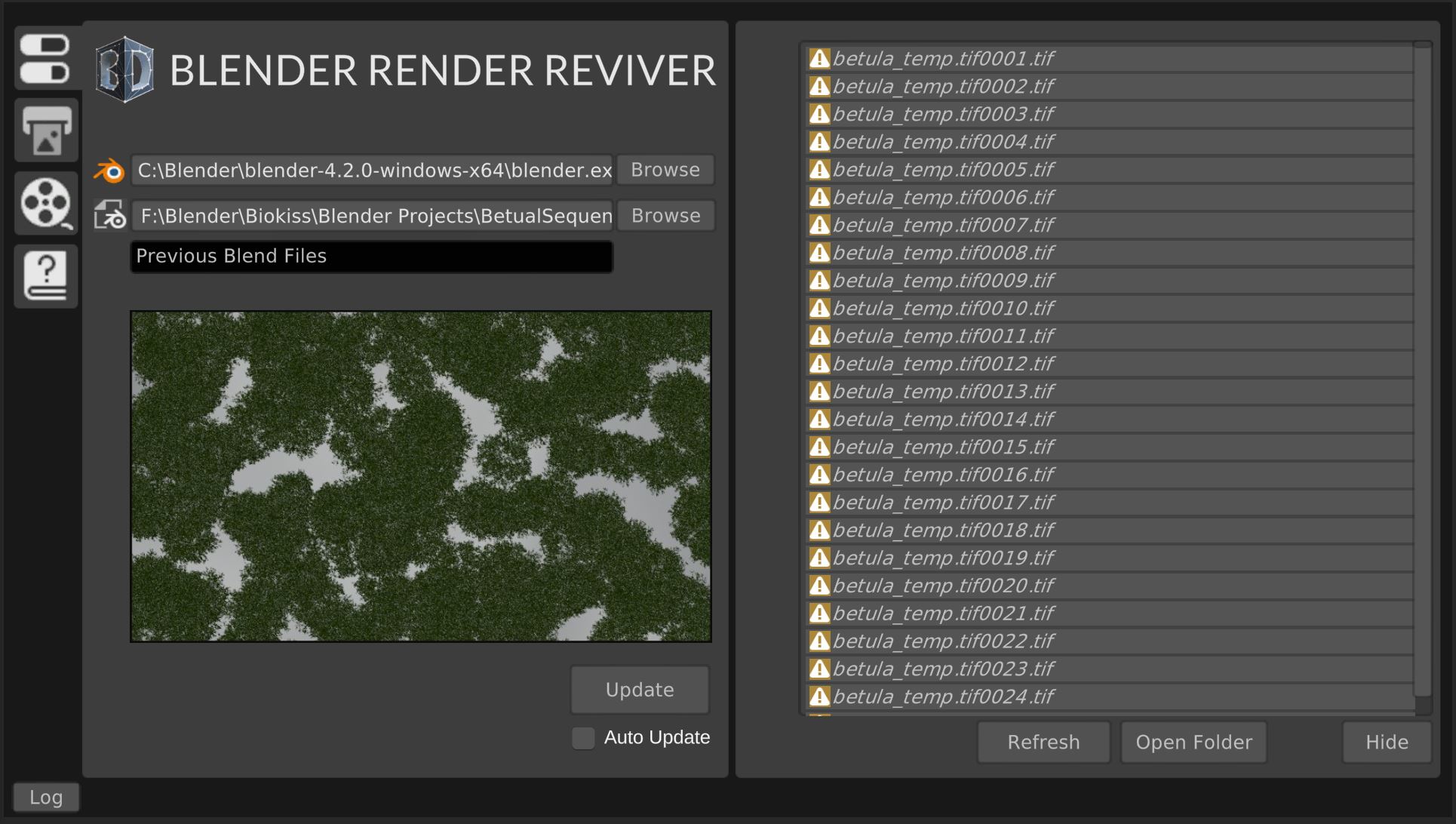
One huge challenge was to figure out which parts of the images were the most important for the inferencer and what parameters of the procedural generation would influence it the most. For that we created an addon that would allow us to run inference right inside Blender. This way we could get a rough idea how much influence on the recognition individual elements of the image had. For example even when there were clearly visible shadows of the tree trunks, they still were largely ignored by the AI.
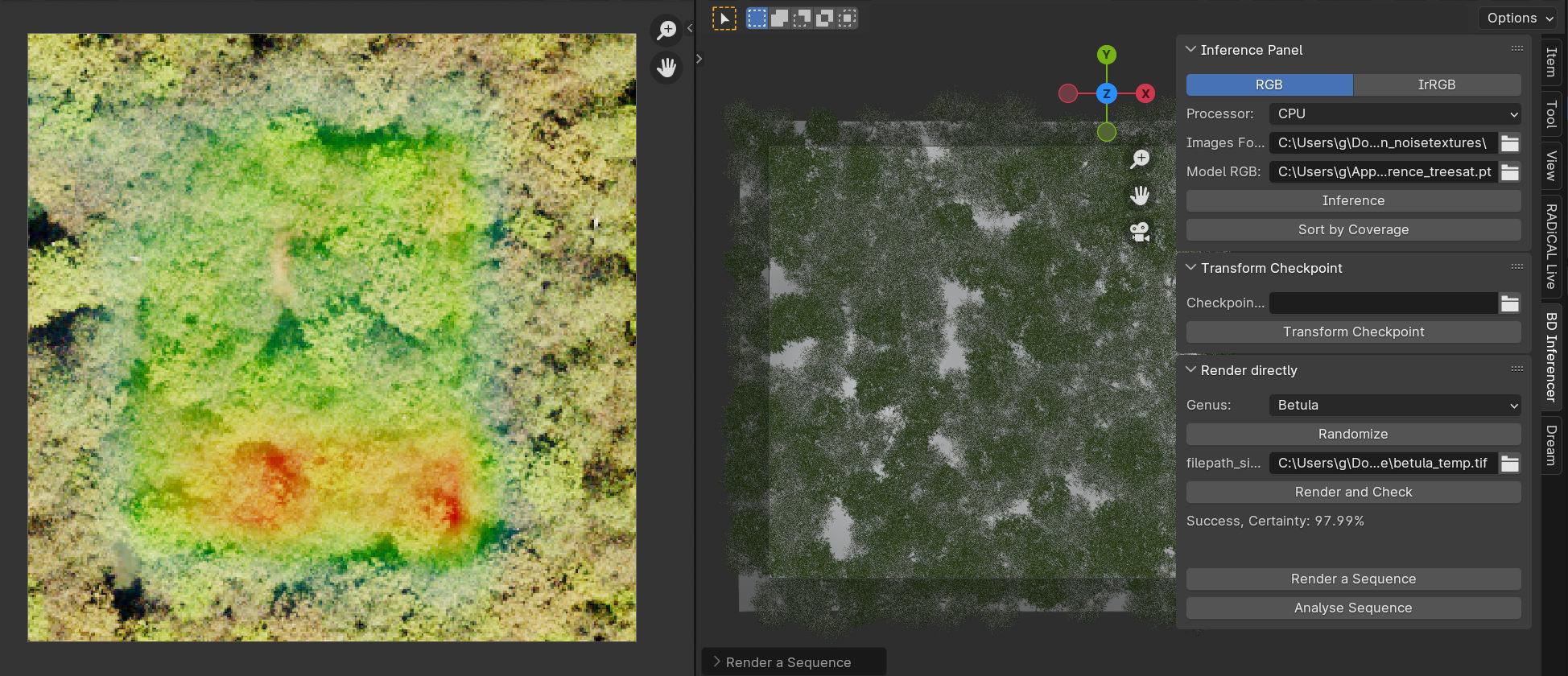
Removing images with a low inference score from the training set actually decreased the precision of the model.
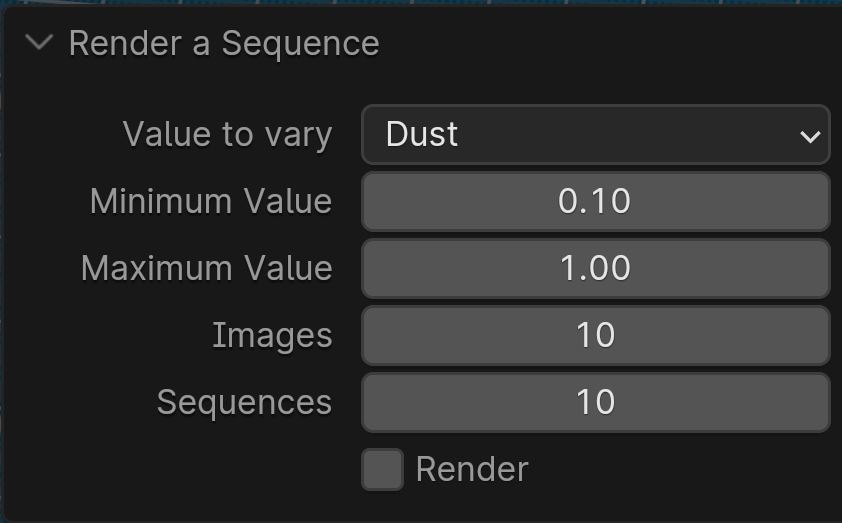 The initial tests did not contribute much to the improvement of the predictions. The original images were taken by cameras mounted on airplanes. There was no consistency in time of year, time of day, weather condition and so on. So we decided to randomize more parameters. We extended the addon in order to render sequences of images, where one parameter was randomized for each sequence: atmospheric dust, sun elevation and rotation, tree density and so forth. The success rate improved slightly, but we were ready to analyze the data some more, in order to find out parameters specific to different species of trees.
The initial tests did not contribute much to the improvement of the predictions. The original images were taken by cameras mounted on airplanes. There was no consistency in time of year, time of day, weather condition and so on. So we decided to randomize more parameters. We extended the addon in order to render sequences of images, where one parameter was randomized for each sequence: atmospheric dust, sun elevation and rotation, tree density and so forth. The success rate improved slightly, but we were ready to analyze the data some more, in order to find out parameters specific to different species of trees.
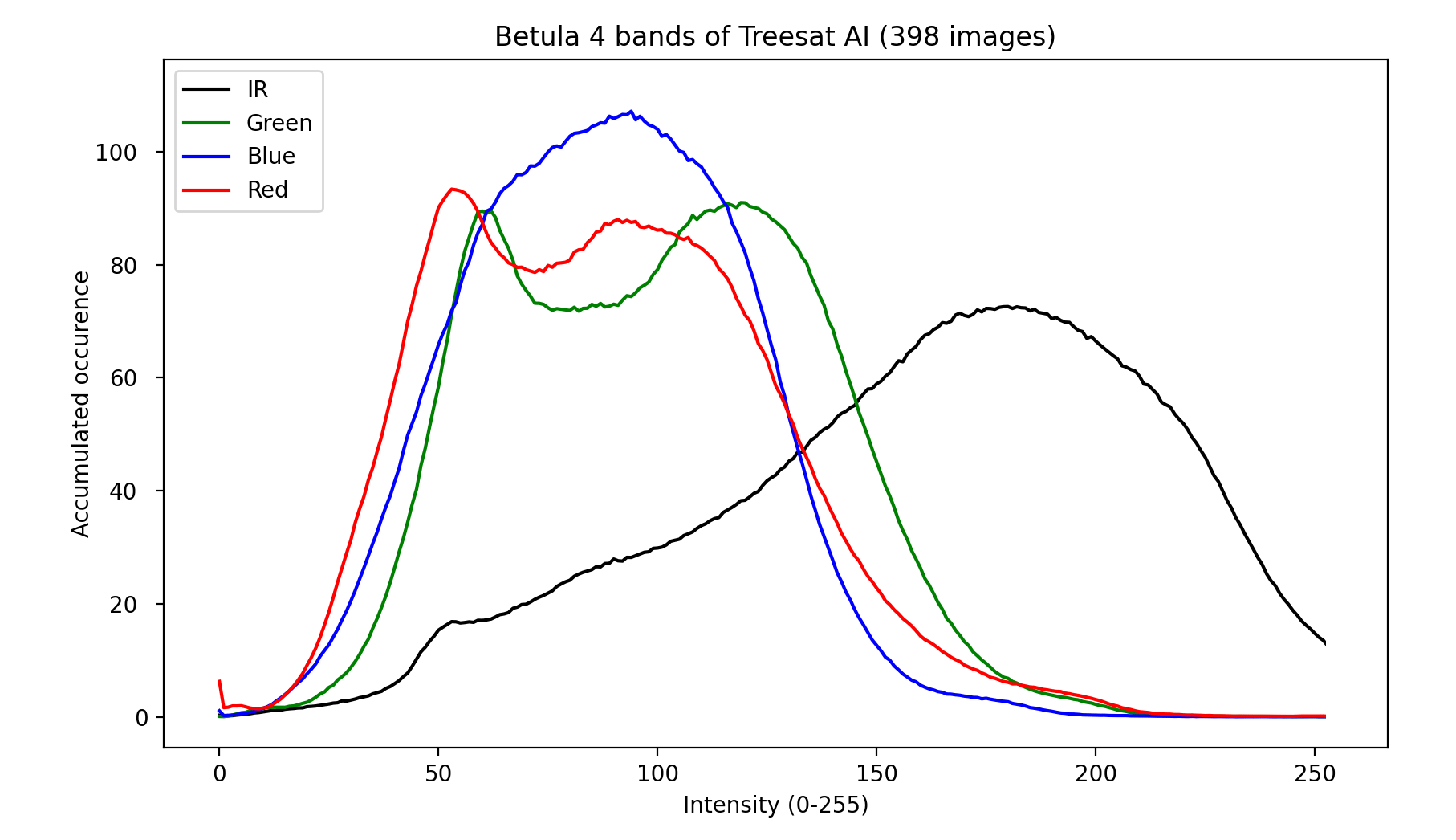
These histograms were quite different for each species, but ensuring the histogram of our images roughly resembled this curve was fairly difficult. Sorting out images that failed to represent this curve would mean a huge increase in rendered files. So we tried to match it in the material of individual trees before placing them.
So what was the biggest challenge?

When rendering single objects from a distance and angle we are actually used to, ideally with corresponding CAD files, photorealism is easy nowadays. You can usually tell when something is off or unrealistic. But what about low resolution photographs taken from an airplane, potentially through clouds? When you can't judge the quality / realism of a synthetic image yourself, it's hard to make real progress.
In the end through thorough analysis and a lot of trial and error, we managed to increased the precision of inference for birch forests by 10 percentag points.
Due to insecurity in fundings, unfortunately the project was put on hold.